Le codage des caractères
 Un domaine où les conventions sont la base du décodage est le codage des lettres : télégraphe de Chappe, code Morse, code braille, etc....
Un domaine où les conventions sont la base du décodage est le codage des lettres : télégraphe de Chappe, code Morse, code braille, etc....
Dans le monde numérique le premier codage fit son apparition en 1960 avec le code ASCII.
Codage ASCII
 L'American Standard Code for Information Interchange est un codage par lequel les caractères courant (imprimables ou non) sont codés grâce à un mot de 8 bits (un octet).
L'American Standard Code for Information Interchange est un codage par lequel les caractères courant (imprimables ou non) sont codés grâce à un mot de 8 bits (un octet).


 Exemple : La lettre G correspond au code hexadécimal $47
Exemple : La lettre G correspond au code hexadécimal $47
Unicode
L'inconvénient d'ASCII est qu'il ne permet pas l'échange d'information entre des pays n'utilisant pas le même alphabet.
Le codage Unicode permet de pallier à cet inconvénient en offre une table bien plus étendue allant jusqu'à 110 000 caractères à l'heure actuelle.
Les caractères dans la norme UNICODE sont codés de 1 à 4 octets
Les caractères sont groupés en blocs en fonction de leur usage et des écritures supportées, et reçoivent une identification numérique unique appelée point de code, identifiée généralement sous la forme U+xxxx (où xxxx est un nombre hexadécimal de 4 à 6 chiffres, entre U+0000 et U+10FFFF).
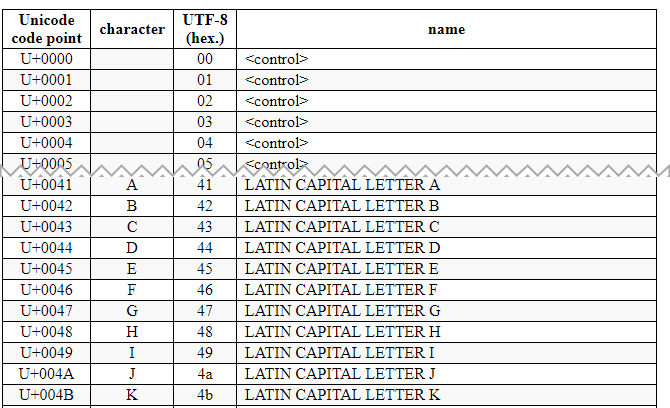
Le caractère A par exemple est codé en U0041
UTF-8
Unicode est un ensemble de caractères et UTF-8 est l'un des algorithmes utilisables pour les encoder en mémoire.
L'UTF-8 est codé sur 8 bits mais il existe des UTF-16, UTF-32 etc.
L'avantage d'UTF-8 est qu'il reste compatible avec le codage ASCII.
L'usage des codages doit être précisé dans les fichiers transmis par l'Internet pour permettre une bonne interprétation.
Principe de codage :
- Si le bit de poids fort de l’octet est à 0, il s’agit d’un caractère ASCII codé sur 7 bits.
Par exemple « A » (A majuscule) a pour code ASCII 65 et se code en UTF-8 par l'octet 65 (45 en hexa). - Sinon, les premiers bits de poids fort de l’octet indiquent le nombre d’octets utilisés pour encoder le caractère à l’aide d’une séquence de bits à 1, se terminant par un bit à 0.
Par exemple : 198=11000110 : la séquence 110 indique un codage sur deux octets
ou encore :227=11100011 indique un codage sur 3 octets. - Dans le cas d’un codage sur n octets, les octets qui suivent l’octet de poids fort doivent commencer par la séquence 10xxxxxx.
Exemple : 227 180 140 = 11100011 10110100 10001100
Le code du caractère est 0011 1101 0000 1100 U+15628
227 précise que le caractère st codé sur 3 octets
L’octet code le caractère chinois?: 㴌
Autre exemple : 0xe2 0x82 0xac = 11100010 10000010 10101100
le numéro du caractère est : 0010 0000 1010 1100 = U+8364 et c’est le caractère €
Un dernier exemple : 0xf0 0x9d 0x82 0x9e = 11110000 10011101 10000100 10011110 : On reconstitue le code :
0001 1101 0001 0001 110 = U+53534 F